Six layers. No blind spots.
Most tools cover one layer. H7 closes the entire loop — from kernel observation to court-admissible attestation, including what it couldn't see.
eBPF syscall probe captures every behavioral event at the kernel layer — no agent can hide from its own syscalls.
Dual-channel ingestion (kernel QII + semantic SII) builds a unified intent model: what the agent did AND what it meant to do.
Every event is sealed into a SHA-256 hash chain and signed Ed25519. The ledger attests even its own blind spots — no interval is silently lost.
The Muraille LSM layer issues a kernel-level veto before a malicious syscall completes. No alert latency — the action never happens.
Cryptographic canaries in fake .env files trap attackers — including AI agents. The first credential-use seals DECEPTION_TRIGGERED conf=1.0. Zero false positives by construction.
One .cal bundle satisfies DORA Art. 17, NIS2 Art. 21, and EU AI Act Art. 9 — offline-verifiable, no SaaS, no third-party CA required.
CI/CD pipeline compromise — detected and certified in 4.8 seconds
A third-party CI runner integrated into a cloud deployment pipeline was compromised via supply-chain injection. The attacker used only legitimate syscalls — invisible to EDR and prompt-injection filters alike.
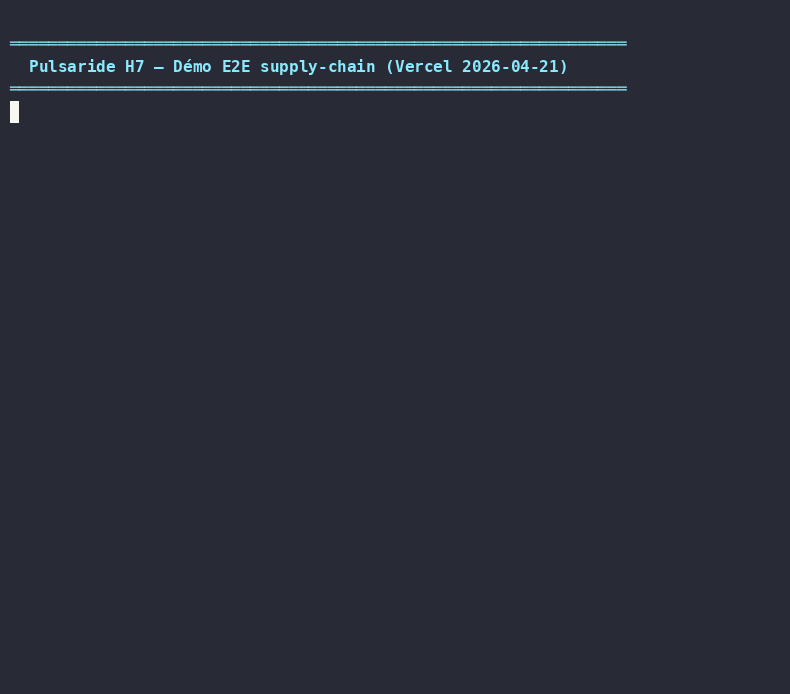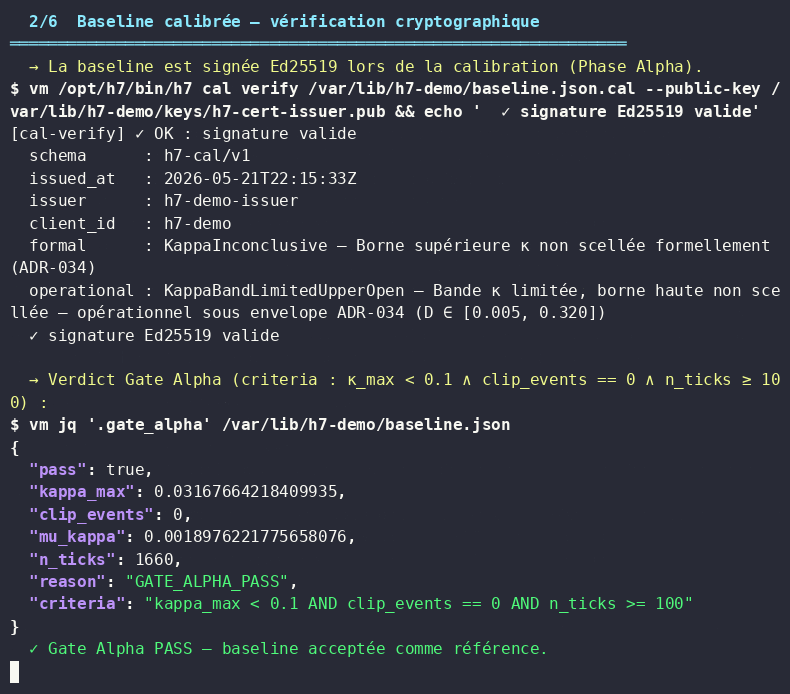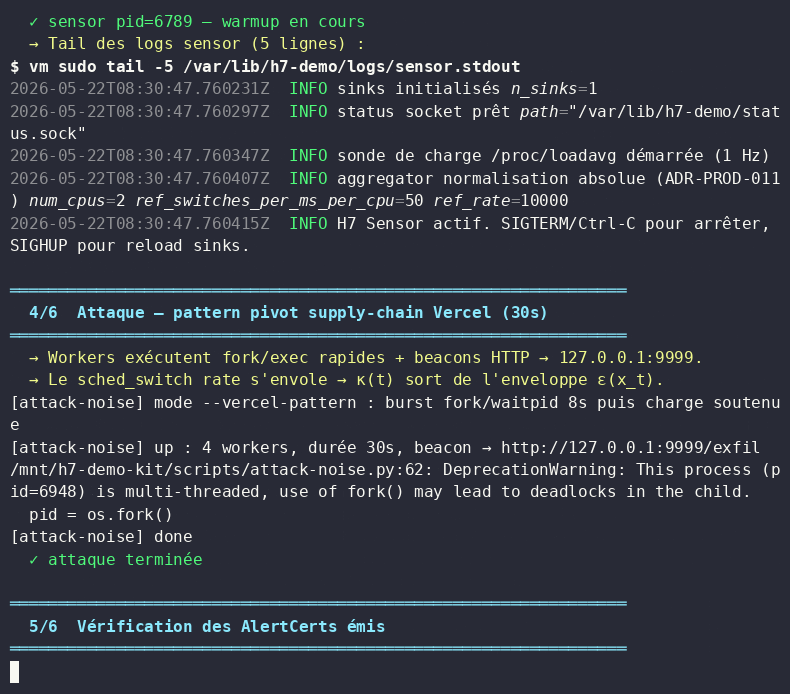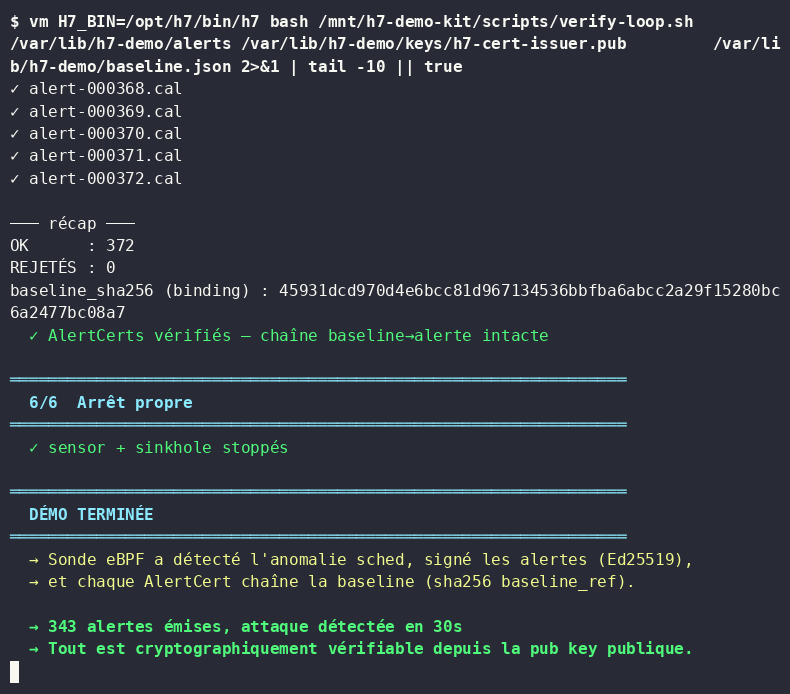
H7 detected the behavioral drift within 4.8 seconds and emitted a .cal certificate — a non-repudiable forensic artifact satisfying DORA Art. 17 incident reporting requirements.
See an agent compromise detected and certified — in 10 minutes
Technical transparency, by design
Every H7 design decision is auditable. No hidden network calls, no opaque SaaS dependency, no trust requirement beyond a cryptographic key you control.
Rust no_std
The H7 probe runs as a Rust no_std eBPF program — no heap, no kernel module, no OS dependency beyond the Linux kernel itself.
CPU overhead
Measured under sustained production load. The kernel sismograph adds no perceptible latency to the agent workload under observation.
Fully offline
Verification of any .cal certificate requires no network access, no external CA, no SaaS. The Ed25519 public key is the only dependency.
No dedicated hardware
H7 runs entirely in software via eBPF — no DPU, no SmartNIC, no proprietary chip required. Runs on-premise, on sovereign cloud, or on standard VMs. No US hardware supply-chain dependency.
Shape the DORA-ready AI agent attestation standard.
We're onboarding regulated EU finance teams as founding partners — H7 in your environment at cost, direct engineering access, and a signed DORA audit package.
From proof-of-concept to DORA-ready in 6 weeks
A fixed-scope engagement: H7 deployed on your agents, .cal certificates in production, and your team fully autonomous on attestation workflows.
Custom pricing available for enterprise contracts. Contact for MSSP and reseller terms.
One .cal bundle. Three regulatory frameworks.
The same attestation certificate satisfies DORA, NIS2, and the EU AI Act — without requiring separate tooling, separate processes, or separate evidence trails.
DORA · Art. 17
Digital Operational Resilience Act
DORA mandates documented, reproducible evidence of ICT incident timelines. H7 .cal bundles provide timestamped, cryptographically-signed kernel traces that satisfy Art. 17 incident reporting with a single artifact.
NIS2 · Art. 21
Network & Information Security Directive 2
NIS2 requires organizations to implement supply-chain security measures and demonstrate continuous monitoring. H7 provides behavioral attestation of third-party agents across the full software supply chain.
EU AI Act · Art. 9
EU Artificial Intelligence Act
The EU AI Act imposes strict logging and audit-trail requirements on high-risk AI systems. H7 .cal certificates serve as the opposable forensic record for autonomous agent runtime behavior demanded by Art. 9.